




How VMware vCenter UUID Duplicate ID Misconfiguration Can Affect the AWS CloudEndure and Elastic Disaster Recovery Solution
By: Brandon Prasnicki, Technical Architect and Gabriel Zabal, Cloud & Cybersecurity Consultant
What is CloudEndure and Elastic Disaster Recovery (EDR)?
AWS CloudEndure from Amazon Web Services and AWS Elastic Disaster Recovery are both Disaster Recovery solutions that continuously replicate your machines (including operating system, system state configuration, databases, applications, and files) into a low-cost staging area in your target AWS account and preferred Region. While the AWS Elastic Disaster Recovery is the preferred solution moving forward, only CloudEndure was available in the AWS region in the configured Customer AWS region at the time of this particular project and writing of this article.
In the case of a disaster, you can instruct CloudEndure Disaster Recovery to automatically launch thousands of your machines in their fully provisioned state in minutes.
By replicating your machines into a low-cost staging area while still being able to launch fully provisioned machines within minutes, CloudEndure Disaster Recovery can significantly reduce the cost of your disaster recovery infrastructure.
You can use CloudEndure Disaster Recovery and AWS Elastic Disaster Recovery Solution to protect your most critical databases, including Oracle, MySQL, and SQL Server, as well as enterprise applications such as SAP.
The Issue
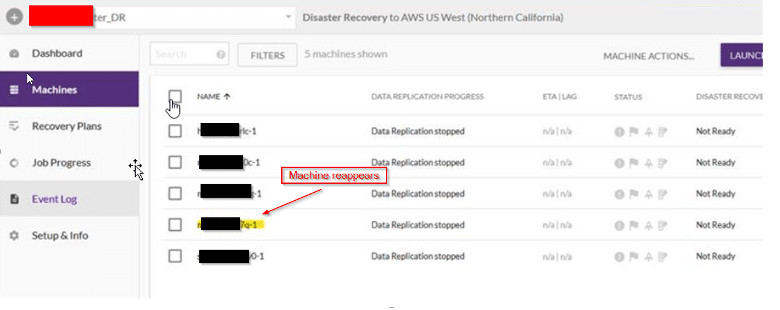
Recently during a CloudEndure implementation, an odd behavior was observed in the CloudEndure console. The customer source environment was VMware vCenter and when machines would begin replicating and were showing replication status in a list, the servers would suddenly disappear from the list. Then in a short period of time, they would suddenly reappear. While this project was using CloudEndure, it is very likely this issue would also be seen in the new AWS Elastic Disaster Recovery solution as the agent and replication design is very similar.
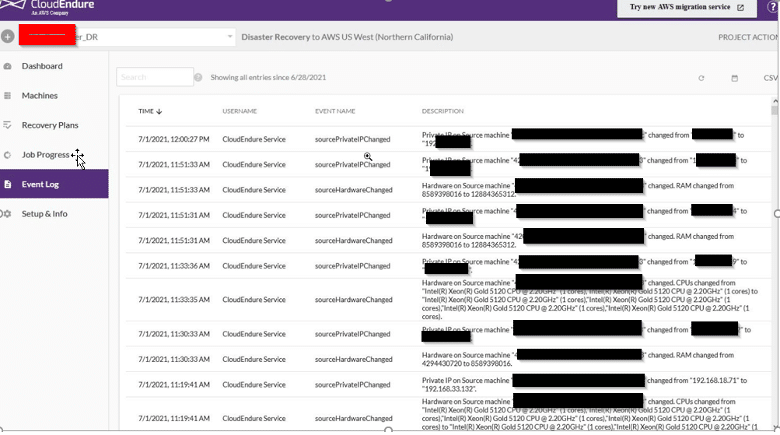
The CloudEndure console provides Event Logging, and in this case, the logging was very helpful. Below you can see a message stating that the hardware on the machine changed. No hardware changes were anticipated, and certainly not this frequently.
After some internet research, it seemed likely that this behavior was due to duplicate UUIDs in the VMware vCenter environment. The CloudEndure Agent generates an ID upon installation based on the Hardware ID, and in the case of the VMware virtual machines, this ID is based on the UUID. This leads to having different Agents with the same ID.
This issue is likely due to cloning configuration and not instructing VMware cloud director to create new UUIDs when using a vApp Template. This VMware KB mentions that when you use VMware Cloud Director, all virtual machines that are created from a vApp Template receive the same VM UUID.
To confirm, these commands were run on the various hosts:
c:wmic bios get name,serialnumber,version
c:wmic csproduct get name,identifyingnumber,uuid
Once the problem machines were identified, the fix to the CloudEndure agents was as follows:
1. Uninstall The CloudEndure Agent:
Windows 64-bit
- Copy the following folder to a new location:
- C:Program Files (x86)CloudEnduredist
- From the new location, run in CMD as an administrator:
- install_agent_windows.exe –remove
Windows 32-bit
- Copy the following folder to a new location:
- C:Program FilesCloudEnduredist
- From the new location, run in CMD as an administrator.
- install_agent_windows.exe –remove
Uninstalling an Agent from a Linux Target machine:
- Run as root or with sudo the following commands:
- /var/lib/cloudendure/stopAgent.sh
- /var/lib/cloudendure/install_agent –remove
2. Re-install the CloudEndure Agent using the steps from the Cloud Endure documentation found here:
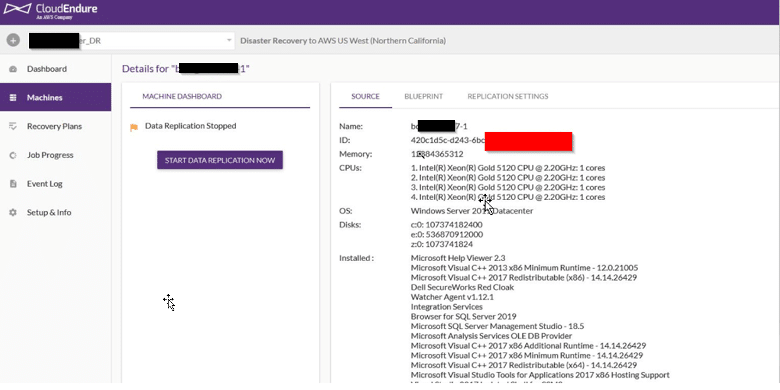
After re-installation, verify the ID is a unique value per machine:
For references see:
https://vcloudvision.com/2021/02/06/duplicate-vm-uuid-because-of-vmware-cloud-director/