







































Splunk Issue: Indexers Failing to Rejoin the Cluster (Solved)
Yetunde Awojoodu | Splunk Consultant
Indexers failing to rejoin the cluster can cause serious issues, but this blog will provide simple steps to help resolve the issue in your environment. First, indexers in a Splunk environment can be clustered or non-clustered. In an indexer cluster environment, there can be two or more indexers also called peer nodes. Each peer node indexes external data, stores them, and simultaneously sends and receives replicated data. These indexing and replication activities are coordinated by a cluster master. The cluster master is also responsible for managing the configuration of peer nodes, searching of peer nodes and remedial activities if a peer goes offline.
A peer node will need to be connected to the cluster master and stay connected to receive instructions. There are however situations in which a peer node could become disconnected from the cluster master. A peer could go offline intentionally by issuing the CLI offline command or unintentionally as in a server crashing or due to intermittent or recurring network issues in the environment.
When a peer gets disconnected from the cluster master and the master does not receive a heartbeat after a set period, the master begins bucket fixing activities to ensure the defined replication factor is met so that the cluster remains in a healthy state. Refer to Splunk docs if you are interested in learning more about what happens when a peer goes down.
Depending on the reason for the disconnection, indexers in a cluster may go offline for a few minutes or hours. In my situation, a partial datacenter outage had caused multiple appliances to fail and resulted in failed connections among the Splunk servers. This caused about half of the indexers to lose connection to the cluster master for several hours.
The datacenter issue was later determined to be a result of storage shortfalls and was resolved within 24 hours but once the datacenter was restored, however, we noticed the indexers failing to rejoin the cluster. The master would not allow them back into the cluster.
Problem Indicators
There were multiple errors in Splunk that pointed to issues with the indexers:
i. Messages indicating failed connection from Cluster Master to the Indexers
ii. Messages indicating indexers being rejected from joining the cluster
iii. Cluster Master in an unhealthy state – Replication and Search factor not met
iv. Most Splunk servers including search heads in red status
v. No replication activities as seen on the Indexer Clustering Dashboard on the Cluster Master
vi. Indexers with “BatchAdding” status on the Indexer Clustering dashboard
Below is a screenshot of some of the error messages seen in Splunk:
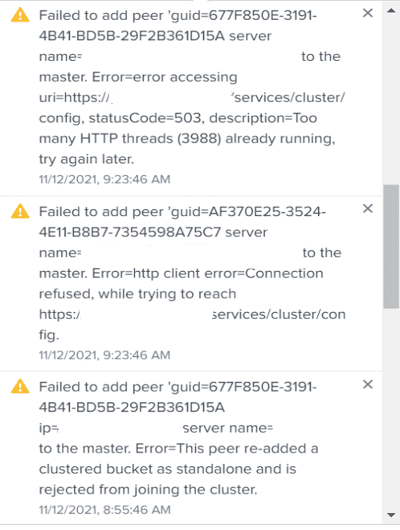
What Happened?
We found that during the datacenter outage, the disconnected indexers continued to perform activities such as rolling hot buckets to warm using the standalone bucket naming convention rather than the naming convention for buckets in a clustered environment. Since the cluster master did not recognize the standalone buckets it didn’t stop those specific indexers failing to rejoin the cluster. More on this
The screenshot below shows examples of standalone nonreplicated buckets:

Below is another screenshot of what buckets originating from the local indexer in a cluster should look like:

*Note that the buckets prefixed with “rb” are replicated buckets from other indexers in the cluster.
Solution
The solution is to rename each standalone bucket to cluster bucket convention. This was a manual effort that took us a few hours to complete but it may be possible to develop a script especially if there are several indexers failing to rejoin the cluster. In my scenario, we had a total of 9 indexers of which 5 were disconnected.
Below are steps to resolve the issue:
i. Identify the indexers that are unable to join the cluster
ii. Put the Cluster Master in maintenance mode
iii. Stop Splunk on one indexer at a time
iv. Locate the standalone buckets in the indexed data directories on each indexer. The default location is $SPLUNK_HOME/var/lib/splunk/*/db/
v. Append the cluster master GUID to the standalone buckets.
vi. Start Splunk
This process requires great attention to detail to avoid messing up the bucket names. I will recommend having other members of your team on a video conference to watch out for any errors and validate any changes made.
How to Locate and Rename Each Bucket
To locate the erroneous buckets, we developed a regex to match the expected format and issued a find command on the CLI to identify them.
➣ find /opt/splunk/var/lib/splunk/* -type d -name “db*” | grep -P “db_\d*_\d*_\d*$”
*Make sure to replace “/opt/splunk/var/lib/splunk/*” with your specific indexed data directory path
On each indexer, go to each data directory in the results from the “find” command and scroll through to identify the bucket names missing the local indexer guid. Once found, append the correct local indexer guid to the bucket name as it appears in the other bucket names. Note that the guid to be appended is different for each indexer. It is the guid for the local indexer so make sure to copy the correct guid from another bucket on that indexer or check $SPLUNK_HOME/etc/instance.cfg file on that indexer for the correct guid to be appended. As a precaution, feel free to back up the buckets (or just rename to .old) before appending the guid and delete the old directories once the indexers are restored.
Bucket Name Format without Guid – db_<newest_time><oldest_time><bucketid>
Bucket Name Format with Guid – db_<newest_time><oldest_time><bucketid>_<guid>
Once you have appended the correct guid to each standalone bucket, the bucket name will look like this as shown in a screenshot above:
db_1640917434_1639072107_161_E56FC9B8-EACF-4D96-8B76-4E28FCF41819
Remember to restart each indexer after the changes have been made and watch out for status changes and replication activities on the indexer clustering dashboard. Note that you may need to wait for a few hours to get the cluster back to a healthy state but not much should be required once the indexers have been restarted.
If you experienced similar errors, as shown above, these simple steps should help resolve the issue in your environment.
If you need additional assistance wrangling your Splunk indexer storage.
You can always contact one of our Splunk specialists here.