



The Nitty-Gritty of Sorting Lexicographically in Splunk
By David Allen, Senior Splunk Consultant
In Splunk, especially in relation to sorting, we often hear the word “lexicographical”. But what does lexicographical really mean and how does Splunk decide the lexicographical precedence that it uses? We will answer this question by taking a deep dive into the most basic building blocks of computer software – binary numbers and a decades old table used today to sort all our modern-day data analytics results. Let’s get started!
Lexicographically is a sorting process based on UTF-8 and more specifically ASCII which is an abbreviation for American Standard Code for Information Interchange. ASCII is a character encoding method originally developed for electronic communications. ASCII codes represent text in computers, telecommunication equipment and other devices.
The history of ASCII reaches back to the early 1960s and is based upon an 8-bit byte. Seven of the bits are used to define the symbol codes and 1 bit was used for the parity – a rather simple form of error detection not used any longer. Back in those days there was a lot of work being done to make a standard for communication from computers to other devices, namely printers, teletype machines and even punch card machines. In addition to the printable characters (upper case, lower-case, numbers and some white space characters), there are a lot of non-printable control characters designed to control certain features not used much today, i.e. the backspace and bell codes among others.
There were a lot of revisions to the ASCII code table down through the years as the standard evolved into what we use today as the accepted ASCII standard below.
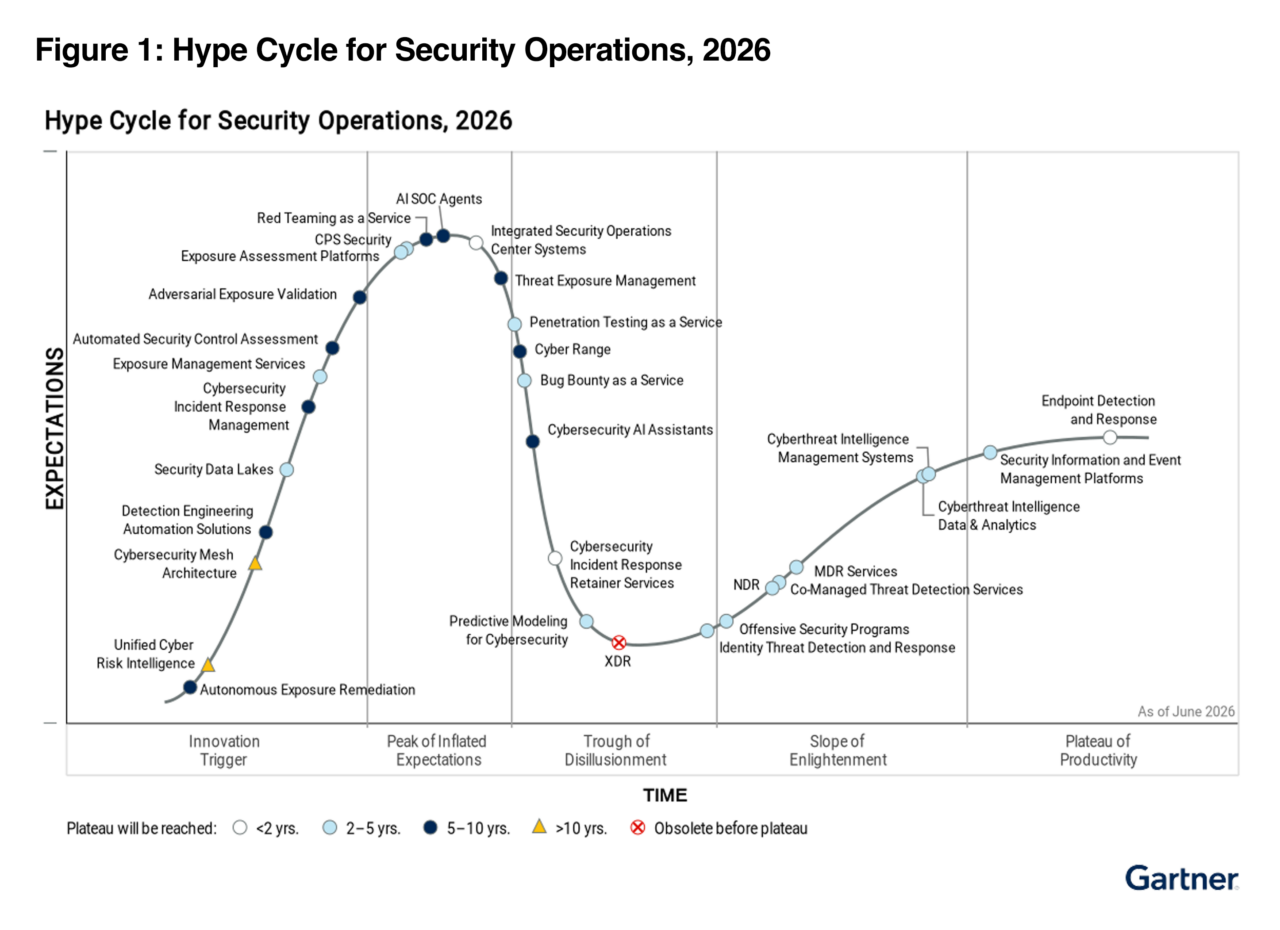
Now, back to Splunk and the lexicographical sorting process… By sorting from the lowest bits (00000002 to the highest bits 011111112) top left to bottom right, we can now see why Splunk states the sorting precedence is as follows…
Numbers are sorted before letters
This is because the number 0 has an ASCII code of 001100002 and the last number 9, has a binary code of 001110012 and these codes are less than the lowest code for the letters which happens to be the capital letter A with a binary code of 010000012.
Uppercase letters are sorted before lowercase letters
This is because the uppercase letters all have binary codes (010000012 – letter A through 010110102 – letter Z) lower than the lowest lower-case letter (letter a) with a binary code of 011000012.
Symbols are not standard. Some symbols are sorted before numeric values. Other symbols are sorted before or after letters
This can be seen by noticing that there are some symbol codes which are lower than the number 0 code. Notice that 001000002 (which is the code for the space symbol) through 001011112 (which is the code for the / symbol are lower codes than the code for number 0. In the same way, there are symbol codes between the numbers and the upper-case letters as well as the upper- and lower-case letters. As a result, when you are sorting symbols along with numbers and letters there may appear to be an anomaly where the symbols are all mixed up among the letters and numbers but in fact it is all makes sense if you sort by the binary codes used in the ASCII table.
Punctuation strings are sorted lexicographically
You may think this does not make much sense. But by looking at the ASCII codes for the punctuation symbols it starts to become clear what is going on. Let’s look at some scrambled up symbols and characters then let’s sort them lexicographically according to the ASCII table and see what we get. Below is the SPL for this example:
| makeresults
| eval ASCII_Symbol=”{ O u ( 3 I A o < 1 E 5 [ I U ? a ! e . \ 7 }”
| makemv delim=” “ ASCII_Symbol
| mvexpand ASCII_Symbol
| sort 0 ASCII_Symbol
| stats list(ASCII_Symbol) AS ASCII_Symbol
| nomv ASCII_Symbol
Here is the output:

Now by looking at these results and comparing with the ASCII table above you can see that the symbols “!”, “(“ and “.” have lower binary values than all the numbers and letters. Also, the symbols “<” and “?” have binary codes higher than the numbers but lower than the upper-case letters and so forth with the remaining symbols. Going from left to right you will see the lowest symbol code to the highest symbol code.

There you have it. Splunk sorting explained at the binary level. So, the next time you hear lexicographical sorting, just think ASCII sorting! That is all it is, plain and simple.