




Splunk Disaster Recovery Architecture
By Brent Mckinney, Senior Splunk Consultant and Jon Walthour, Technical Architect
This blog proposes a comprehensive architecture for implementing Disaster Recovery (DR) in Splunk Enterprise running on AWS. This example includes setting up two multi-site SmartStore indexer clusters, and a single search head cluster stretched across two AWS regions. Our SmartStore objects will be s3 buckets in AWS. This 2-region solution ensures uninterrupted search and indexing capabilities in the case that one of the regions become unavailable.
Let’s start with our indexer tier.
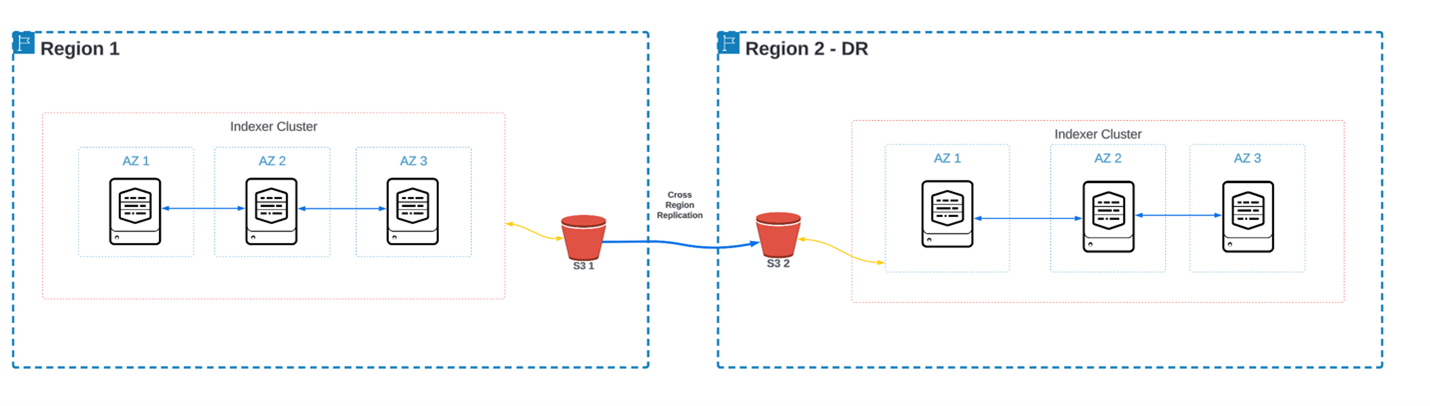
For our indexer tier, we have two unique multi-site indexer clusters each belonging to a separate region. For the implementation stage, this means building TWO individual indexer clusters separate from each other. The “sites” will be the availability zones in each region, so region 1 will have 3 sites (AZ 1, AZ 2, and AZ 3) and likewise in region 2. Each cluster will also be SmartStore enabled, having their own external S3 bucket.
Note: Indexers with SmartStore enabled will offload Splunk buckets to S3 once they roll from hot to warm. From there, retention is managed within S3. Before enabling SmartStore, we first need to create an S3 bucket in AWS and ensure read/write capabilities from the splunk indexers. See AWS documentation for details on S3 bucket creation and permissions.
We first need to adjust server.conf on the Cluster Manager node. Because this is a multisite cluster, buckets being migrated need to be able to identify the origin and replicate across all sites. We can accomplish this by setting the following on the Cluster Manager node:
server.conf
[clustering]
contrain_singlesite_buckets=false
To enable SmartStore on our indexers, we need to update indexes.conf in the indexes app under $SPLUNK_HOME/etc/manager-apps.
indexes.conf
[volume:smartstore]
storageType = remote
path = s3://<name_of_s3_bucket>
remote.s3.access_key = <s3_access_key>
remote.s3.secret_key = <s3_secret_key>
remote.s3.endpoint = http|https://<s3_host_url>
[default]
remotePath = volume:smartstore/$_index_name
repFactor = auto
The first stanza [volume:smartstore] contains the configurations to point and authenticate to the S3 bucket. The [default] stanza configs here point the remote path to this SmartStore volume and sets the replication factor to auto to enable replication of Splunk buckets.
The above configuration additions need to happen on BOTH indexer clusters, as they are still technically separate, and unaware of each other. Before configuring the DR piece of the solution, we need to have 2 standalone multi-site indexer clusters with SmartStore enabled, in a healthy state.
Disaster Recovery
The DR solution comes into play by enabling AWS Cross Region Replication from the S3 in region 1 to region 2. Once data is offloaded from the Splunk indexers to the S3 bucket in region 1, AWS then replicates that data to the S3 bucket in region 2.
In region 2, the indexers will utilize S3 for searches that require warm data retrieval during search operations, which will now contain data that has been replicated from region 1 – up to a 15 min delay per AWS SLAs. This allows data to be highly searchable in the case that the indexer cluster and/or S3 bucket in region 1 becomes unavailable.
The idea here is that if region 1 becomes unavailable, users can query the indexers in region 2 and still see data that was indexed in region 1. Splunk SmartStore paired with AWS Cross Region Replication allows for this disaster recovery architecture.
Search Tier
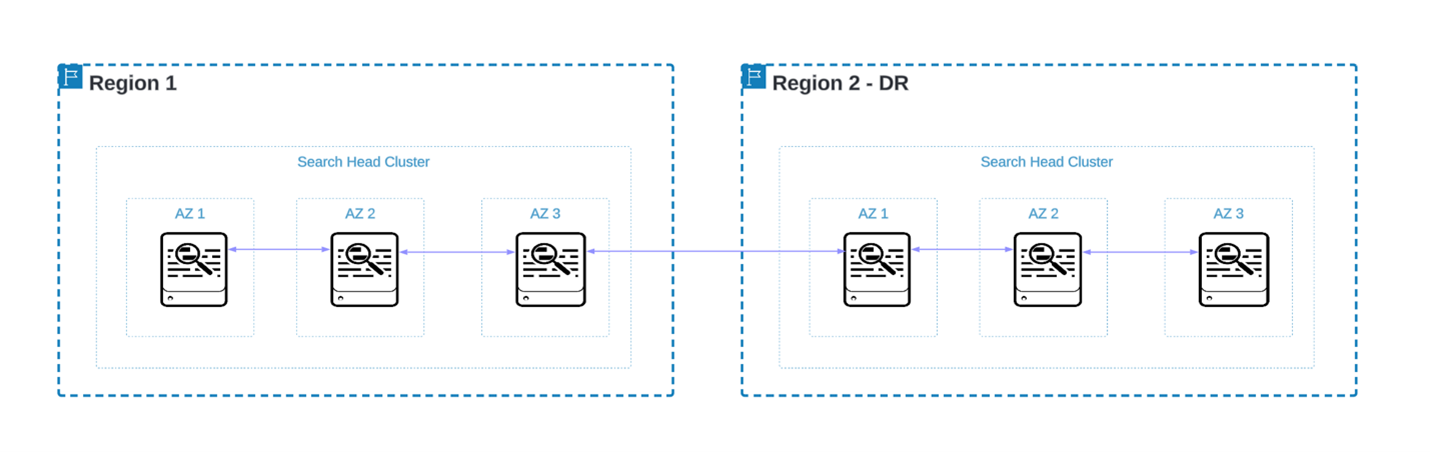
For the search tier, we have a stretched search head cluster across both regions. The reason we want to have this as a single cluster, rather than broken out into 1 per region like the indexers, is to allow for easy replication of knowledge objects. This will ensure that user content created in region 1 is easily accessible in the case that users need to log into region 2.
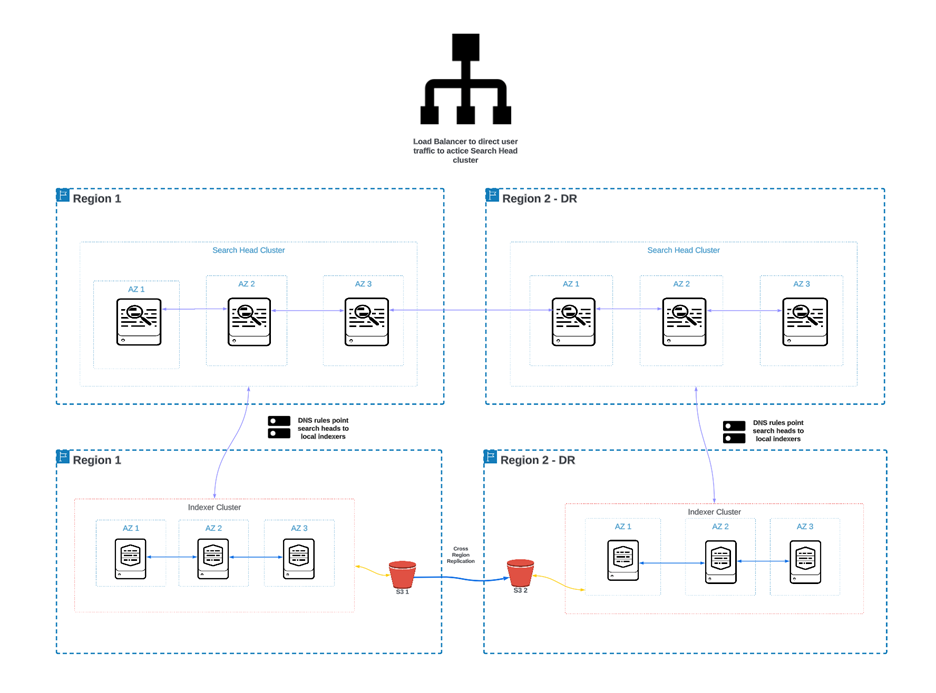
From a technical standpoint, Splunk does not allow for members of a single search head cluster to have different search peers, the search peers must be consistent across all members. To ensure that search heads in region 1 are only peered to indexers region 1, and likewise for region 2, we can utilize DNS names for the indexers, so that each search head points to the same name but resolves to it’s local indexers per the DNS rules in each region.
This will satisfy the technical need for all Splunk Search Heads to have a consistent list of the same search peers across both regions, but behind the scenes only dispatching searches to the indexers in the same region as the search head.
Architecture
Overall, this is the high-level architecture that can be implemented to ensure HA between both Search Heads and Indexers.
We hope this has provided the overview that will help you build your own disaster recovery architecture. Contact us if you need additional information. Happy Splunking!