
Data Cleansing in Splunk
Data Cleansing in Splunk
By: Zubair Rauf | Splunk Consultant
Data is the most important resource in Splunk. Having clean data ingestion is of utmost importance to drive better insights from machine data. It is eminent that data onboarding process should not be automated and every step should be carefully done as this process can determine the future performance of your Splunk environment.
When looking at the health of data in Splunk, the following metrics are important:
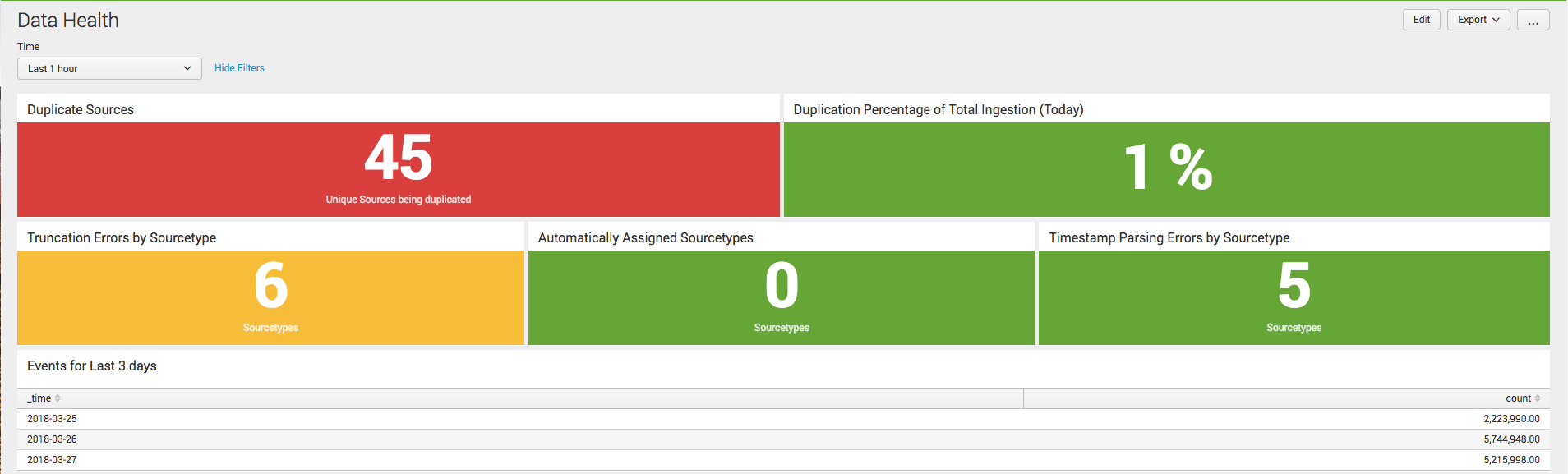
- Data parsing
- Automatically assigned sourcetypes
- Event truncation
- Duplicate events
Data parsing
Data parsing is the most important when it comes to monitoring data health in Splunk. This is the first step that is performed by Splunk when data is ingested into Splunk and indexed into different indexes. Data parsing includes event breaking, date and time parsing, truncation, and parsing out fields that are important to the end user to drive better insights from the data.
Splunk best practices recommend using these six parameters when defining every sourcetype to ensure proper parsing.
- SHOULD_LINEMERGE = false
- LINE_BREAKER
- MAX_TIMESTAMP_LOOKAHEAD
- TIME_FORMAT
- TIME_PREFIX
- TRUNCATE
When these parameters are properly defined, Splunk indexers will not have to do spend extra compute resources in trying to understand the log files it has to ingest. In my experience auditing Splunk environments, Date is one field that Splunk has to work the hardest to parse if it is it is not properly defined within the parameters of the sourcetype.
Automatically assigned sourcetypes
Sometimes when Splunk sourcetypes are not defined correctly, Splunk starts using its resources to parse events automatically and creates similar sourcetypes with a prefix number or a tag. These sourcetypes will mostly have a few events and then another one would be created.
It is important to see that such sourcetypes are not being created, as they will again contribute to data integrity being lost and search/dashboards will omit these sourcetypes as they are not part of the SPL queries that make the dashboard. I have come across such automatically assigned sourcetypes at multiple deployments. It becomes necessary to revisit and rectify the errors in sourcetype definition to prevent Splunk from doing this automatically.
Event truncation
Splunk truncates events by default when they exceed 10,000 bytes. There are some events that exceed that limit and are automatically truncated by Splunk. XML events generally exceed that limit. When an event is truncated before it ends, that harms the integrity of the data being ingested in Splunk. Such events omit complete information and therefore they have no use in driving insights and skew the overall results.
It is very important to always go back and monitor all sourcetypes for truncated events periodically so that any truncation errors can be fixed and data integrity can be maintained.
Duplicate events
Event duplication is one more important area to consider when looking at data integrity. At a recent client project, I came across almost multiple hundred gigabytes of duplication in events in an environment that was ingesting almost 10 TB of data per day. Duplication of the data can be due to multiple factors and sometimes while setting inputs, the inputs can be duplicated. Duplicate data poses a threat to the integrity of data and the insights driven from that data. Duplicate data will also take up unwanted space on the indexers.
Duplication of events should also be periodically checked, especially when new data sources are on-boarded. This is to make sure that no inputs were added multiple times. This human error can be costly. At a client where we found multiple gigabytes of duplication, 7 servers were writing their logs to one NAS drive, and then the same 7 servers were sending the same logs to Splunk. That caused duplicate events amounting to almost 100GB/day.
Ensuring that the areas mentioned above have been addressed and problems rectified, would be a good starting point towards a cleaner Splunk environment. This would help save time and money, substantially improve Splunk performance at index and search time and overall help you drive better insights from your machine data.
If you have questions, or would like assistance with cleansing and improving the quality of your Splunk data, please contact us: