



Identifying Logon Anomalies with Splunk Mltk
By Kamal Dorairaj, Senior Splunk Consultant
Goal:
The goal of this deep dive is to identify, when there are unusual volumes of failed logons as compared to the historical volume of failed logins in an environment. Increase in failed logins can indicate potentially malicious activity, such as brute force or password spraying attacks. Alternatively, these failed logins can also identify potential misconfigurations in service account permissions or misconfigured organizational unit (OU) groups for standard users.
Data Sources:
The following are data sources used for monitoring failed logins in this deep dive: okta.
The deep dive leverages the “oktaim2:log” source type.
Algorithm:
DensityFunction algorithm.
Model Creation:
Run the actual search for the last 30 days in the ‘search’ section of the MLTK app.
It gives us the understanding of our available dataset. The more the data, the better for the model.

Add the fit statement to use DensityFunction algorithm and save into a model, as shown below:
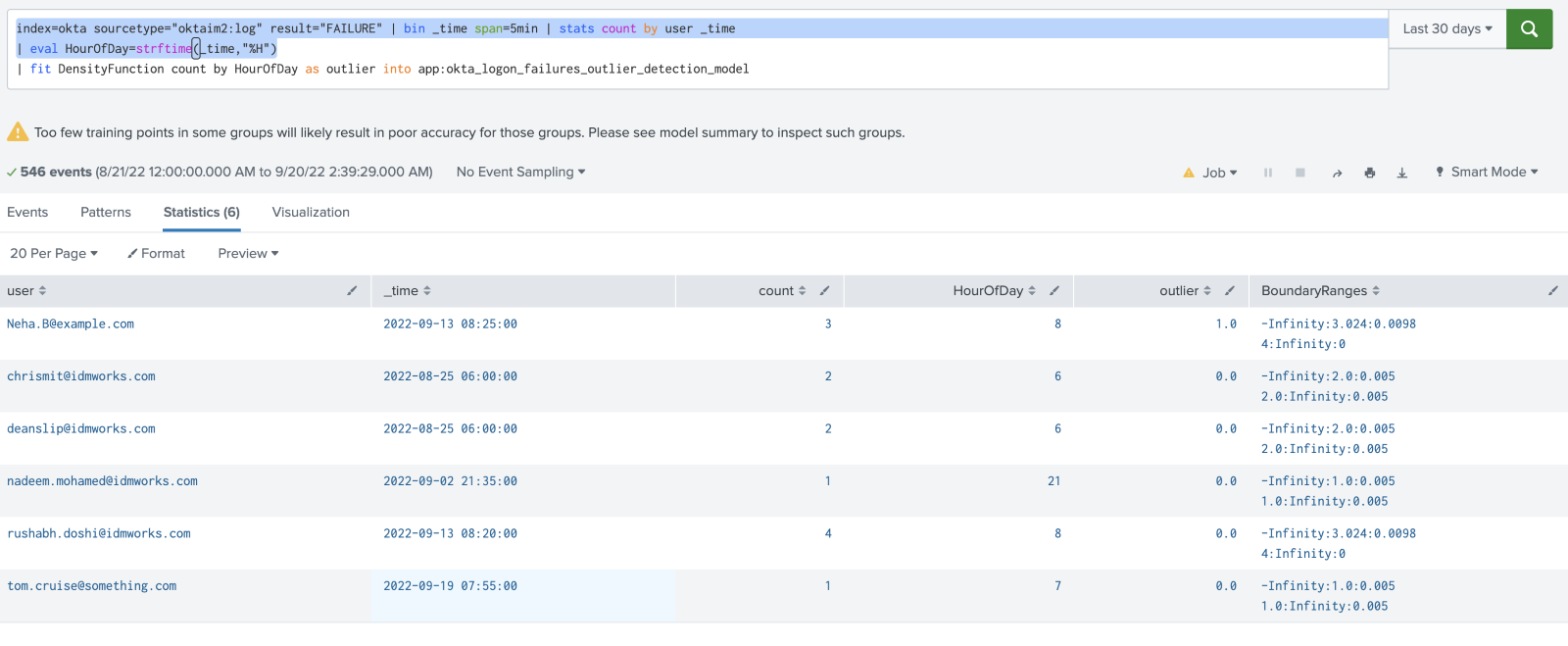
The above search counts the number of failed logons per host over 5-minute time intervals, enriches the data with the hour of day, and then trains an anomaly detection model to detect unusual numbers of failed logons by the hour of day. It will now show up under the ‘Model’ section in the MLTK app.
Report Creation:
After you run this search and are confident that it is generating results, save it as a report and schedule the report to periodically retrain the model. As a best practice, train the model every week, and schedule training for a time when your Splunk platform instance has low utilization.
Note: Model training with MLTK can use a high volume of resources.

The above training model currently scheduled to run every month. Please change the scheduling in the future, based on the volume of data that coming in.
Make sure that the permissions for the model are correct. By default, models are private to the user who has trained them, but since you have used the app: prefix in your search, the model is visible to all users who have access to the app the model was trained in.
Apply the Model:
Now that you have set up the model training cycle and have an accessible model, you can start applying the model to data as it is coming into the Splunk platform. Use the following search to apply the model to data. This search can be used to populate a dashboard panel or can be used to generate an alert.
When looking to flag outliers as alerts, you can append | search outlier=1 to the search, to filter your results to show only those that have been identified as outliers. You can save this search as an alert that triggers when the number of results is greater than 0, which can be run on a scheduled basis such as hourly.
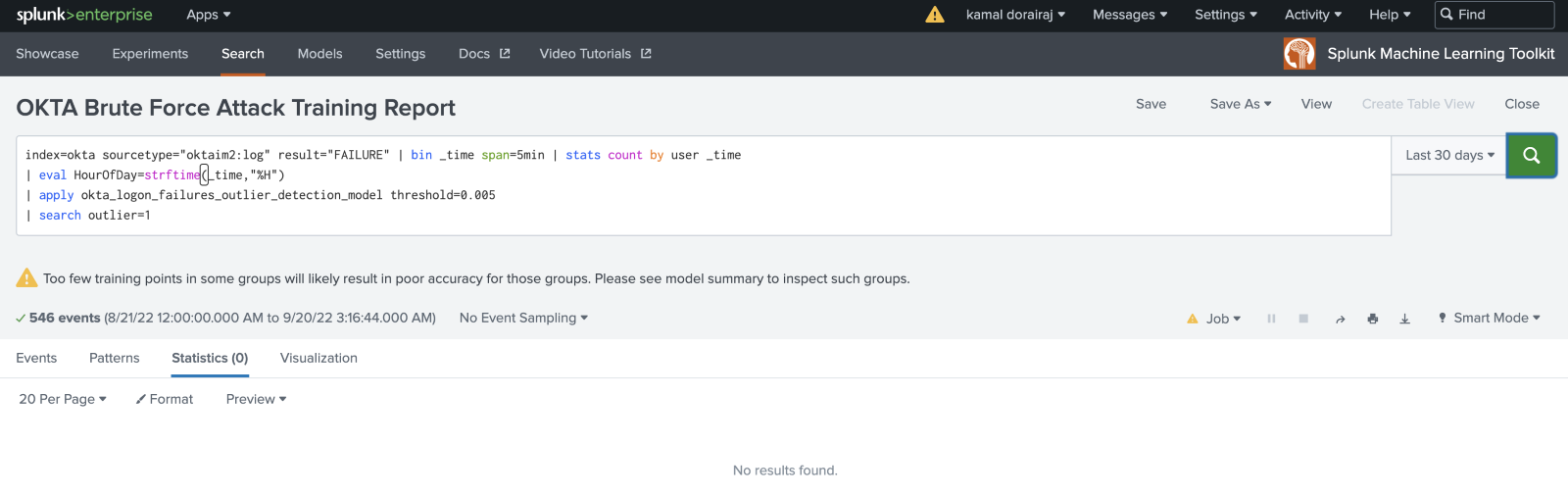
When training and applying your model, you might find that the number of outliers being identified is not proportionate to the data: that the model is either flagging too many or too few outliers. The DensityFunction algorithm has several parameters that can be tuned to your data, creating a more manageable set of alerts.
The DensityFunction algorithm has a threshold option that is set at 0.01 by default, which means it will identify the least likely 1% of the data as an outlier. You can increase or decrease this threshold configuration at the apply stage, depending on the tolerance for outliers, as shown in the search.
Alert:
The Model is now saved as an Alert to run every one hour.
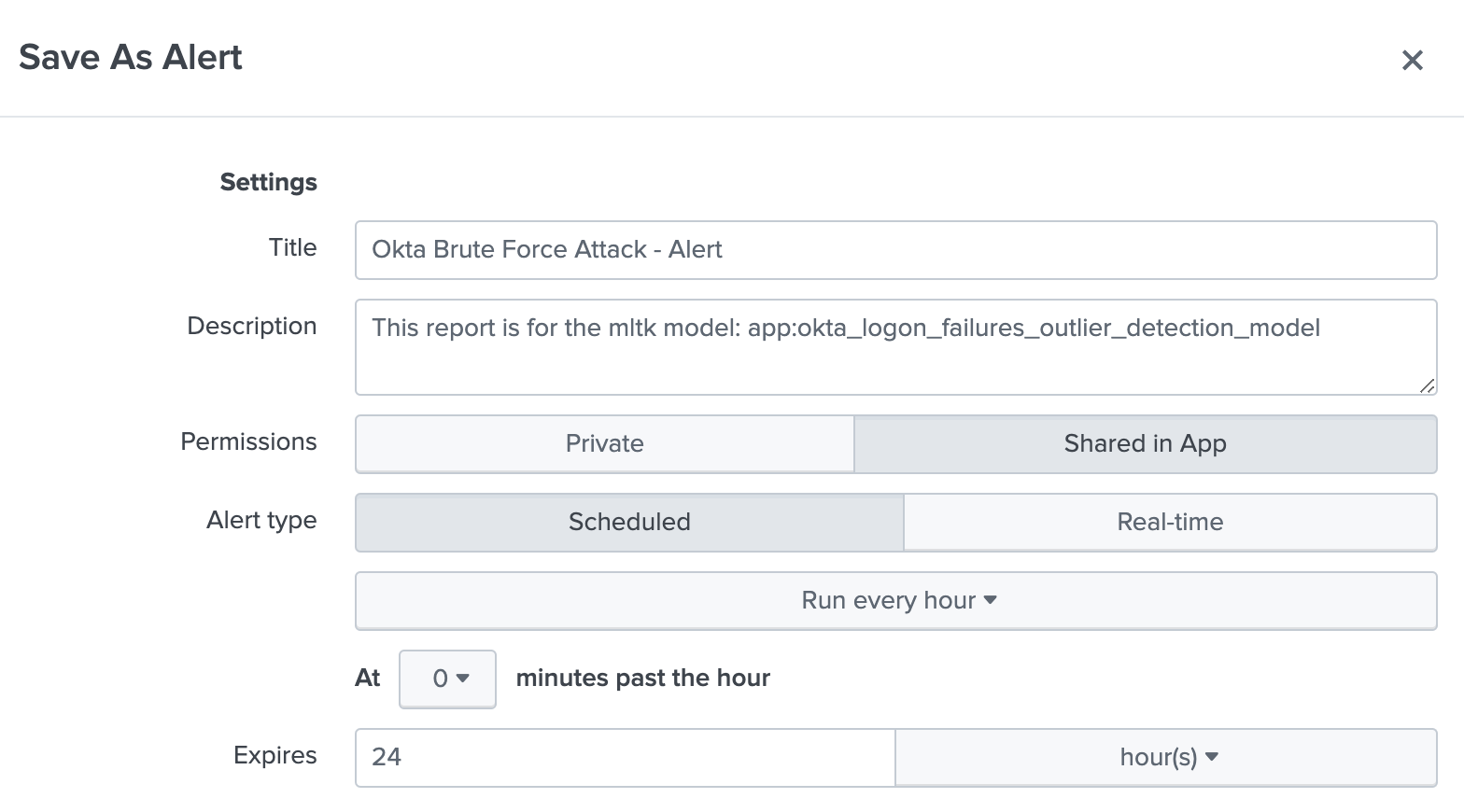
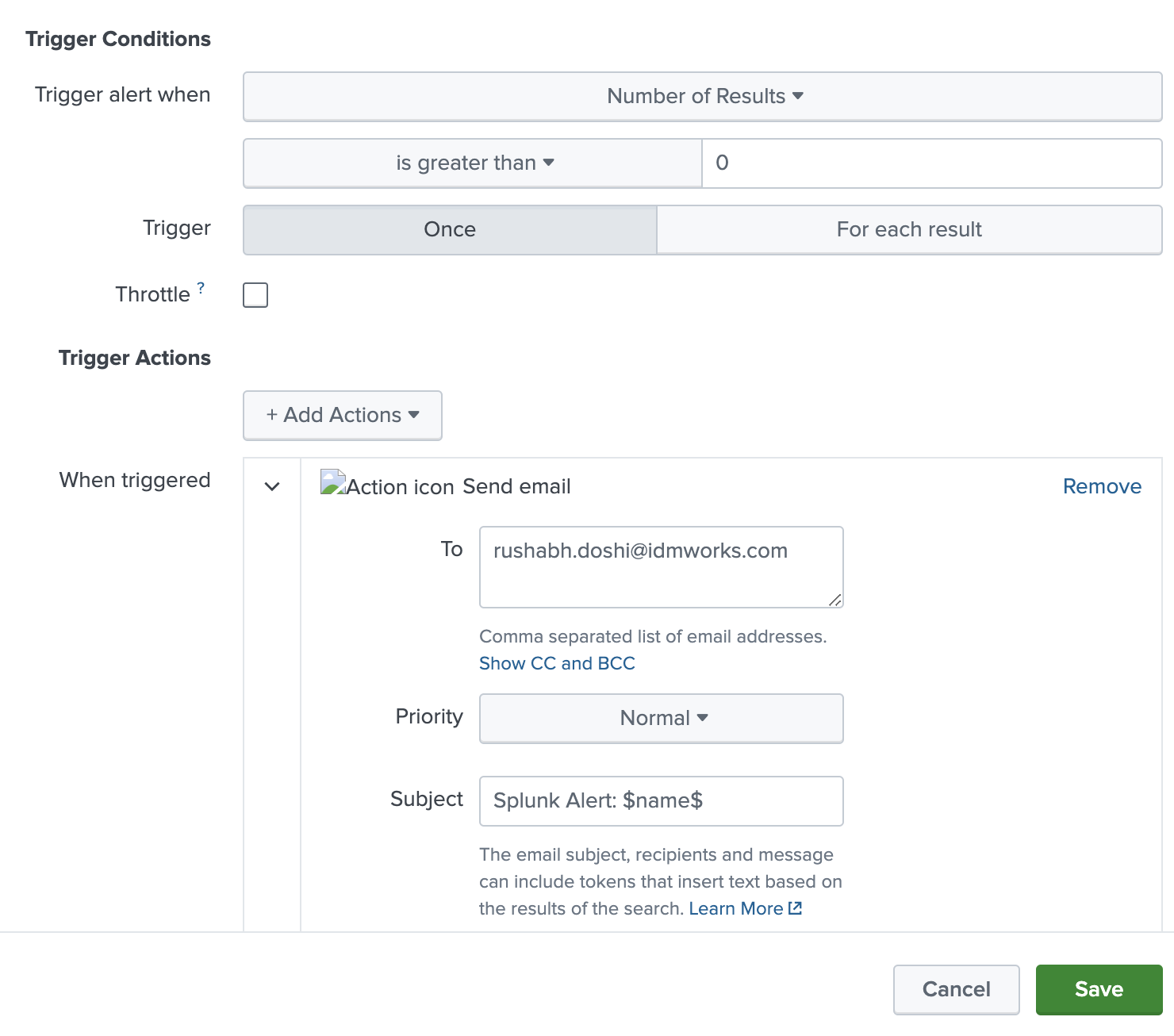

Note: if you got very few data points, there is going to be many false positive alerts. So kindly review it and ingest more data till you are positive on the outlier detection.
Need help building ML-based security detections in Splunk? Talk to TekStream’s experts.
About the Author
Kamal Dorairaj has over 22 years of diverse IT experience with full cycle development of various Applications and Systems. In his first 10 years; he worked as a CRM Consultant at the client locations includes Middle East, India, US; in various domains includes Retail, Telecom, eCommerce. Later he worked as a Lead SRE at Stubhub (was eBay company) for 7 years as a SME in Splunk, GCP. He is a PMP certified, ITIL certified, CompTia Security+ certified and Splunk Architect, Splunk ES Admin, Splunk Developer certified. He also completed Cybersecurity for Managers, Business Analytics from MIT Sloan and MBA in Technology Management. His core interest area has been, ‘Get more business value out of Big data’.