

Using Child Playbooks in Splunk Phantom
By: Joe Wohar | Senior Splunk Consultant
Splunk Phantom is an amazing SOAR platform that can really help your SOC automate your incident response processes. It allows you to build playbooks, which are Python scripts under the covers, that will act on security events that have been ingested into the platform. If you have a well-defined process for handling your security events/incidents, you can build a Splunk Phantom playbook to run through that entire process, therefore saving your security analysts time and allow them to work on more serious incidents.
A common occurrence with Splunk Phantom users is that they create a playbook that they want to use in conjunction with other playbooks. For example, a security analyst created three playbooks: a phishing playbook, an unauthorized admin access playbook, and a retrieve user information playbook. In both a phishing event and an unauthorized admin access event, they’d like to retrieve user information. Therefore, the analyst decides to have each of those playbooks call the “retrieve user information playbook” as a child playbook. However, when calling another playbook as a child playbook, there a few gotchas that you need to consider.
Calling Playbooks Synchronously vs. Asynchronously
When adding a playbook block to a playbook, there are only two parameters: Playbook and Synchronous. The Playbook parameter is simple: choose the playbook you’d like to run as a child playbook. The Synchronous option allows you to choose whether or not you’d like to run the child playbook synchronously.
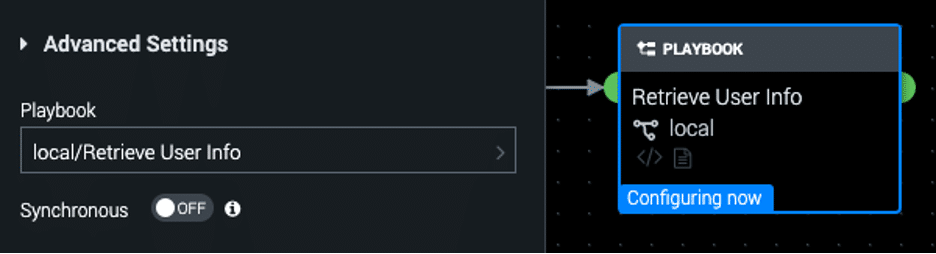
Choosing “OFF” will cause the child playbook to run asynchronously. This means that the child playbook is called to run on the event the parent playbook is running against, and then the parent playbook continues down the path. If you’ve called the child playbook at the end of the parent playbook, then the parent playbook will finish running and the child playbook will continue running separately.
Choosing “ON” means that the parent playbook will call the child playbook and wait for it to finish running before moving on to the next block. So when a child playbook is called, you have two playbooks running at the same time on the event. This means that every synchronous child playbook is a performance hit to your Splunk Phantom instance. It is best to avoid running child playbooks synchronously unless absolutely necessary due to the performance impact.
Since there are cases where you might need the child playbook to be synchronous, there are a few tips to avoid causing too much of a performance impact.
- Keep your child playbooks short and simple. You want your child playbook to finish running quickly so that the parent playbook can resume.
- Avoid adding prompts into child playbooks. Prompts wait for a user to take an action. If you put a prompt into a child playbook, the parent playbook has to wait for the child playbook to finish running and the child playbook has to wait for user input.
- Avoid using “no op” action blocks from the Phantom app. The “no op” action causes the playbook to wait for a specified number of seconds before moving on to the next block in the path. The “no op” block causes the child playbook to take longer to run, which you usually want to avoid, but there are instances where you may need to run a “no op” action in a child playbook (covered later).
- When using multiple synchronous child playbooks, run them in series, not parallel. Running synchronous child playbooks in series ensures that at any given time during the parent playbook’s run, only two playbooks are running at the same time: the parent playbook and one child playbook.
Sending Data Between Parent and Child Playbooks in Splunk Phantom
When calling a child playbook, the only thing that is carried over to the child playbook is the event id number. None of the block outputs from the parent playbook are carried into the child playbook. This creates the problem of how to get data from a parent playbook into a child playbook. There are two main ways of doing this: add the data to a custom list or add data to an artifact in the container. The first option, adding data to a custom list, is a very inconvenient option due to how difficult it is to get data out of a custom list. Also, custom lists are really designed to be a list for checking values against, not storing data to be pulled later.
Adding data to an artifact in the container can be done in two different ways: update an artifact or create a new artifact. Adding data to an artifact is also much easier than adding and updating data in a custom list because there are already actions created to do both tasks in the Phantom app for Phantom: update artifact and add artifact. “Update artifact” will require you to have an artifact id as a reference so it knows which artifact in the container to update. Adding an artifact is simpler because you can always add an artifact, but you can only update an artifact if one exists.
When adding an artifact, there can be a slight delay between the time the action runs and when the artifact is actually added to the container. My advice here is when you add an artifact to a container that you want to pull data from in the child or parent playbook, add a short wait action (you only need it to wait 2 seconds) immediately after the “add artifact” action. You can have the playbook wait by adding a “no op” action block from the Phantom app for Phantom (which you should already have installed if you’re using the add artifact and update artifact actions).
Documentation Tips for Parent and Child Playbooks in Splunk Phantom
When creating a child playbook that you plan to use in multiple parent playbooks, documentation will really help you manage your playbooks in the long run. Here are a couple of quick tips for making your life easier.
- Use a naming convention for the child playbooks at least. I’d definitely recommend using a naming convention for all of your playbooks, but if you don’t want to use a naming convention for parent playbooks, at the very least use one for the child playbooks. Adding something like “ – [Child]” will really make it easier to find child playbooks and manage them.
- Put the required fields for the child playbook into the playbook’s description. Calling a child playbook is very easy, but if your parent playbook isn’t using the same CEF fields as the child playbook, you’re going to have a problem. Adding this list to the description will help let you know if you need to update your container artifact to add those needed fields or not.
Follow these tips and tricks and you’ll be setting yourself up for a performant and easy-to-manage Splunk Phantom instance for the long term.
Want to learn more about using playbooks in Splunk Phantom? Contact us today!