




Three Splunk Commands That Can Cause Loss of Data
By David Allen, Senior Splunk Consultant
Few things in Splunk are more annoying than running searches and finding weeks or months later that data is missing from the results. This can happen primarily when commands are used which are not scalable. They may work initially when your data set is small. But as time goes on and more and more events are getting ingested, bad things may happen and the worst is that you may not even know that you are losing data. Since data is missing, you may not be getting alerts and your dashboards somehow do not look quite right.
So what are these annoying SPL commands that can cause data to be lost? The three main ones are the sort, join and append commands. In this blog we will be going over each of these commands and how they can cause data loss. Fortunately, in Splunk there is usually more than one way to get things done and we will explore ways to not use these commands if you have large datasets or if you expect to have large data sets in the future.
Sort Command
One of the easiest traps to fall into as you start learning Splunk is to use the default limit for the sort command. Did you know that if you run the following sort command that Splunk truncates your events to a count of 10,000?
| sort ipAddressThis one is easy to fix once you find the problem. In this case, just use the limit argument to instruct Splunk how many events to pass through the sort command. So to pass 20,000 events you can do this…
| sort limit=20000 ipAddressYou do not need to preface the limit argument with the text “limit=” you can simply put any number after the sort command. So to pass the entire data set do the following …
| sort 0 ipAddressThis fix is pretty simple. Just remember to ALWAYS put a 0 after the sort command. This will make your life a lot easier. Of course, you can learn the hard way and wait until you see your event count strangely showing 10,000. This should get you thinking – “I keep running this search over and over, how is it possible that I always get EXACTLY 10,000 events?” So, unless you intentionally want to truncate your events to 10000 or some other number remember to ALWAYS put a 0 after the sort command.
Append and Join Commands
Issue 1 – Append and Join are used quite often but did you know that the append and join commands have a 50,000 event limit? This is because these commands use subsearches which Splunk limits to 50,000 events. This limit can be changed in the limits.conf but generally that is not a recommended solution. Now this one may be a little harder to find by just looking at the event count of your search results since the subsearch events are appended to the primary search. So the final result event count may be hundreds of thousands of events and you would never know your subsearch did not return its entire data set.
Issue 2 – Another problem with the Append and Join commands is that the subsearches timeout after 60 seconds and then auto-finalizes if you exceed this maximum execution time. You might not even realize that Splunk has auto finalized, but this is nonetheless why you could be losing LOTS of data.
Issue 3 – Append is a transforming command and Join is a centralized streaming command. Both of these commands are run on the search head as a result Splunk needs to send all the events from all the indexers to the search head when processing hits one of these commands. This is inefficient as there are other ways to keep processing the SPL on the indexers until a transforming command has been reached potentially much later and accomplishing the same results.
Now we know what the issues are, let’s see how to rewrite the SPL to not use the Append and Join Commands unless you are working with small data sets.
Removing Append From Your Searches
Removing the append command it is pretty much a matter of combining the append subsearch with the primary search. Sometimes this is easier said than done. But the general idea is as follows.
This is your original search with an append command:
index = main sourcetype = access_combined
| append [search index = my_index sourcetype = apache_error ]
| eval field1 = “These are distributable”
| eval field2 = “streaming commands running on the search head”
| eval field3 = field1.” “.field2
| stats values(status) AS Status BY host
To remove the append command in this example would change the search to look like this:
(index = main sourcetype = access_combined) OR (index = my_index sourcetype = apache_error)
| eval field1 = “These are distributable”
| eval field2 = “streaming commands run on the indexers”
| eval field3 = field1.” “.field2
| stats values(status) AS Status BY host
The first example sends the results to the search head early on at the append command and then runs the eval commands on the search head. But in the second example, the results are sent to the search head at the stats command making the eval commands run on the indexers. So the second search is more efficient and less burdensome on the search head and returns the entire dataset which does not timeout after 60 seconds.
Removing Join From Your Searches
Here is a typical SPL example with a join command:
index=main sourcetype=access_combined
| join pid [search index=my_index sourcetype=apache_error]
| stats sum(rows) sum(cputime) by pid
In this next example, the inner join is used since the join type is not defined and the default join type is the Inner join. This is shown in the below venn diagram.
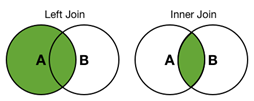
Now let’s look at some ways to do the left join and inner join without using the join command. This search merely includes all events from both sourcetypes.
(index= main sourcetype=access_combined) OR (index=my_index sourcetype=apache_error)
| stats sum(rows) sum(cputime) by pidNow to include the events in both sourcetypes with the same pid you can do this:
(index= main sourcetype=access_combined) OR (index=my_index sourcetype=apache_error)
| stats values(sourcetype) AS Sourcetype sum(rows) sum(cputime) by pid
| eval Count = mvcount(Sourcetype)
| search Count=2In this example when the Count is 2 then the pid value is used in BOTH sourcetypes which is the same as the Inner join command in the diagram above.
The Left Join can be done this way:
(index= main sourcetype=access_combined) OR (index=my_index sourcetype=apache_error)
| stats values(sourcetype) AS Sourcetype sum(rows) sum(cputime) by pid
| eval Count = mvcount(Sourcetype)
| search Count=2 OR (Count=1 AND Sourcetype=access_combined)Another option is to find the events with a pid in one sourcetype that is not in the other sourcetype. So to find the events with a pid in the access_combined sourcetype and not in the apache_error sourcetype use this SPL:
(index= main sourcetype=access_combined) OR (index=my_index sourcetype=apache_error)
| stats values(sourcetype) AS Sourcetype sum(rows) sum(cputime) by pid
| eval Count = mvcount(Sourcetype)
| search Count= 1 AND Sourcetype=access_combinedDistributable vs Transforming Commands
Remember to push transforming commands later in your SPL and do as much work on the indexers as possible BEFORE sending the events to the search head. This is one of the main advantages of using a distributed system. This allows the indexers to run in parallel on small quantities of the events. Then when a transforming command is used all the indexers send their events to the search head where the final wrapup is accomplished and both transforming and distributing commands can be used from that point on.
If you think about it, the indexers can easily run the distributable streaming commands on their small dataset without any issues. But the transforming commands actually need the entire dataset available on all the indexers to do their task. For example, to do a stats command or a sort command the search head needs ALL the events so it would make no sense to run the stats and sort commands on the indexer first then again on the search head.
Distributable Streaming commands (run these first):
eval
where
search
rename
fillnull
fields
mvexpand
etc...
Transforming Commands (run these later in your SPL):
stats
chart
timechart
join
append
transaction
table
eventstats
streamstats
etc…
So, there you go. Next time you feel the need to use the join and append commands, especially if you know you will be using large data sets, try writing your SPL in such a way to not use these commands. Good luck!