

Textract – The Key to Better Solutions
By: Troy Allen | Vice President of Emerging Technologies
Businesses thrive on information, but finding good data can be difficult to collect sort, and utilize due to the vast variety of sources and forms by which information is created and disseminated. As organizations are inundated with documents, forms, data streams, and more it’s becoming more difficult to extract meaningful information efficiently and funnel that information into the systems that need it or present it in a fashion that drives better business decisions. Textract, part of AWS’s ever-growing solutions for Machine Learning, can play a critical part in how businesses process documents and collect vital data for use in their critical solutions and operations.
While Optical Character Recognition (OCR) has been around for many years, many organizations tend to overlook its strengths and ability to improve data processing. Textract, while it does provide OCR functionality as a Cloud-based service, is much more thorough in its ability to bring Machine Learning based models to your business applications. In order for data to be useful, it must first be collected; Textract provides OCR capabilities to ensure text is recognized from paper-scanned documents to electronic forms.
For data to be really useful, it needs to have organization and structure; Textract provides the ability to automatically detect content layout and recognize key elements and the relationship of the text and the elements it discovers. And finally, for data to not only be useful, but actually utilized, it needs to be accessed; Textract can easily share the data, in its context, with other applications and data stores through well-formatted data streams to applications, databases, and other services. Textract is designed to collect and filter data from documents and files so that you don’t have to. Solutions utilizing Textract naturally benefit from an automated flow of information from capture to storage, to retrieval.
Textract is more than just OCR
In 1914, Emanual Goldberg developed a machine that could read characters and convert them into telegraph code. Golderg also applied for a patent in 1927 for his “Statistical Machine”. Goldberg’s statistical machine was designed to retrieve individual records from spools of microfilm by using a movie projector and a photoelectric cell to do pattern recognition to find the right record on microfilm. In many ways, Goldberg’s inventions are often credited as the beginning of Optical Character Recognition technology (OCR). Over the next 92 years, OCR has become one of the most critical elements, which few have heard of, in building business solutions.
OCR moved beyond the business world to enabling sight-impaired people to read printed materials. Ray Kurzweil and the National Federation of the Blind announced a new product in 1976, based on newly developed charged-coupled device (CCD) flatbed scanners and text-to-speech synthesizers, which has fundamentally changed the way we work with information. It was no longer about reports, statistics, or data; it was about sharing information with anyone, in a format that could easily be accessible. By 1978, OCR had moved into the digital world as a computer program.
Like all new technologies, OCR has had its issues and limitations. In the beginning, text had to be very clear and created only in certain fonts to be recognized. Scan quality of physical pages also plays a major factor in how well OCR engines extract the text from pages and in most cases, only a portion of the text is captured on poor scans. Even today, with so many advancements in OCR, there are challenges to accurately collecting and organizing data from images.
Most OCR engines collect all the text from documents and make the words available for search engines, but very few OCR engines take it any further without requiring additional tools and applications. Textract by Amazon Web Services goes beyond OCR by not only collecting the content but understanding where the content came from.
Textract provides the ability to not only perform standard character recognition but is designed to understand the formatting and how content is aligned within a page. This is accomplished by recognizing and creating Bounding Boxes around key information and text areas to support the content, table extraction, and form extraction.
Item Location on a Document Page
The example image displays content that is separated by columns and has header information.

Figure 1 – Two Column Document Example
Most OCR applications will collect all the words on the page, but do not provide a reference to lines of text or location. Amazon’s Textract retrieves multiple blocks of information from each page of the image it investigates:
- The lines and words of detected text
- The relationships between the lines and words of detected text
- The page that the detected text appears on
- The location of the lines and words of text on the document page
As the following illustration demonstrates, Textract is able to identify that there are two columns of information on the page. It then recognizes that for each column, there are multiple lines of text which are made up of multiple words.
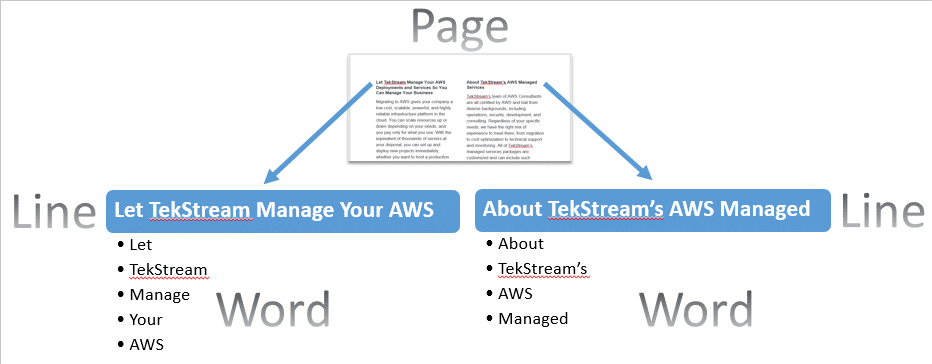
Figure 2 – Textract Line and Word Recognition
Textract outputs its findings in standard JSON files so that they can be utilized easily by other services or applications. The example above would be represented in the JSON as follows:

Figure 3 – Sample JSON
Table Extraction
Amazon’s Textract is well equipped to locate table data within documents as well. Textract recognizes the table construct and can establish key-value pairs with the cells by referencing the row and column information. The following table represents 20 distinct cells, including the header row that will be evaluated by Textract:
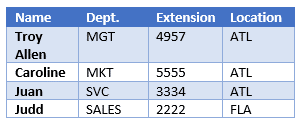
Figure 4 – Sample table data
The output JSON from the Textract service creates a mapping between the rows and columns and intelligently identifies the key-value pairs in the table. This recognition can also be performed against vertical table data rather than horizontal table. The following illustrates the key-value pair matching:
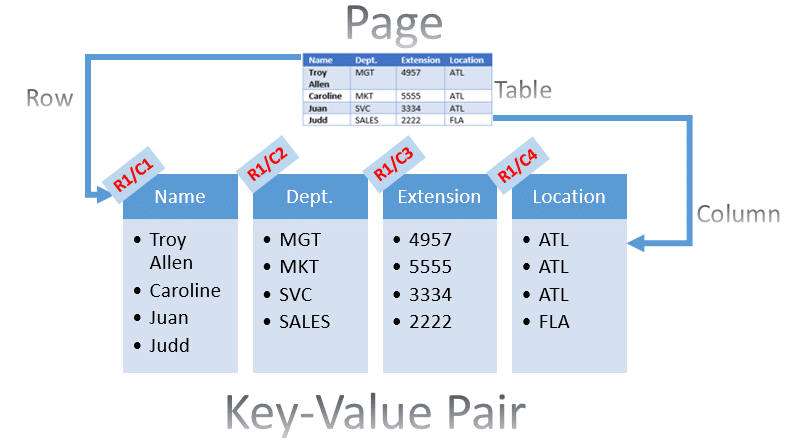
Figure 5 – Table Key-Value Pair
In addition to detecting text, Textract has the ability to recognize selection elements such as checkboxes and radio buttons. A checkbox that has not been selected, such as o or ¡ is represented as a status of NOT_SELECTED whereas R are represented as SELECTED and can be tied to a key-value pair as well. This can be extremely helpful in finding values in both tables and forms.
Form Extraction
Businesses have been interacting with their clients and vendors for decades through forms. Textract provides the ability to read form data and clearly define key-value pairs of information from them. Many organizations struggle with the fact that forms change over time and it can be difficult to train tools to find data when those tools were specific for a particular form layout. Textract removes that complexity by reading the actual text rather than a location on a form to get its information and analyzes documents and forms for relationships between the detected text.

Figure 6 – Sample form image
In the example above, Textract will create the following Key-value pairs:
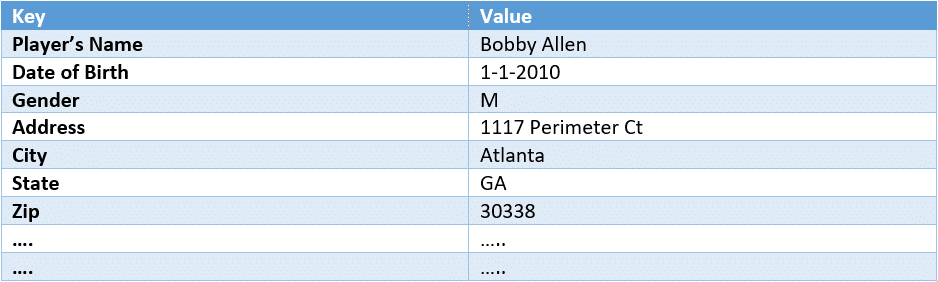
Traditional OCR tools will provide all the available text out of an image or document, but to gather Key-value pairs from forms and data, as well as recognizing text based on words, lines, and understanding the blocking of content, additional tools are required. Textract does all of this for you providing data that can then be further analyzed as needed.
Textract Considerations
Textract is specifically designed to perform OCR against image files such as JPG, PNG, and PDF file formats. Most text-based document formats created electronically today do not require additional OCR since they are already embedded with an index that is accessible by search engines. With the proliferation of mobile device and tablet use, there are still many times that images are created in which there is no inherent index available. We use our phones to take pictures of everything including people, scenes, receipts, presentations, and much more. It is quick and easy to capture the world around us, but it is more difficult to have a computer application capture important information that may be held in those photographs. Textract enables the extraction of data from images so that you don’t have to.
As with all technologies, there are limits to what Textract can do and should be recognized before introducing it into a solution. AWS maintains detailed information about the Amazon Textract service and its limitations and can be found here, https://docs.aws.amazon.com/textract/latest/dg/limits.html.
Putting Textract to Work
While OCR is important and can be a critical part of any business process, it is an engine that retrieves information from sources that could not be accessed except through human intervention. In many ways, it is like an important element within a car’s engine. A fuel injector is critical for a car to run, but may not have much value as an entity unto itself. It’s when you bring various parts together that your car takes you where you need to go or your application drives your business.
To create a basic OCR application with Textract, you will need:
- A place to store the images that need to be processed, in many situations this may be an Amazon S3 service (Simple Storage Service), Amazon WorkDocs (secure content creation, storage, and collaboration service), or even a relational database like Amazon Aurora.
- An application or service to call the Textract services. Many organizations are creating Cloud-first applications and may choose to use AWS Lambda to run their code without having to worry about the servers where the code runs.
- A place to store the results of the Textract services. The options are limitless for where to store the text and details uncovered by Textract, this could be stored back into an Amazon S3 instance, a database like Aurora, or even a data warehouse like Amazon Redshift.
- And finally, you need to do something with the information you have collected. This all depends on what your goals are for the information, but at a minimum, most people want to search for information. Using Amazon Elasticsearch Service is an easy way to allow people to find the new information Textract was able to gather for you.
The following outlines this simple Textract solution:
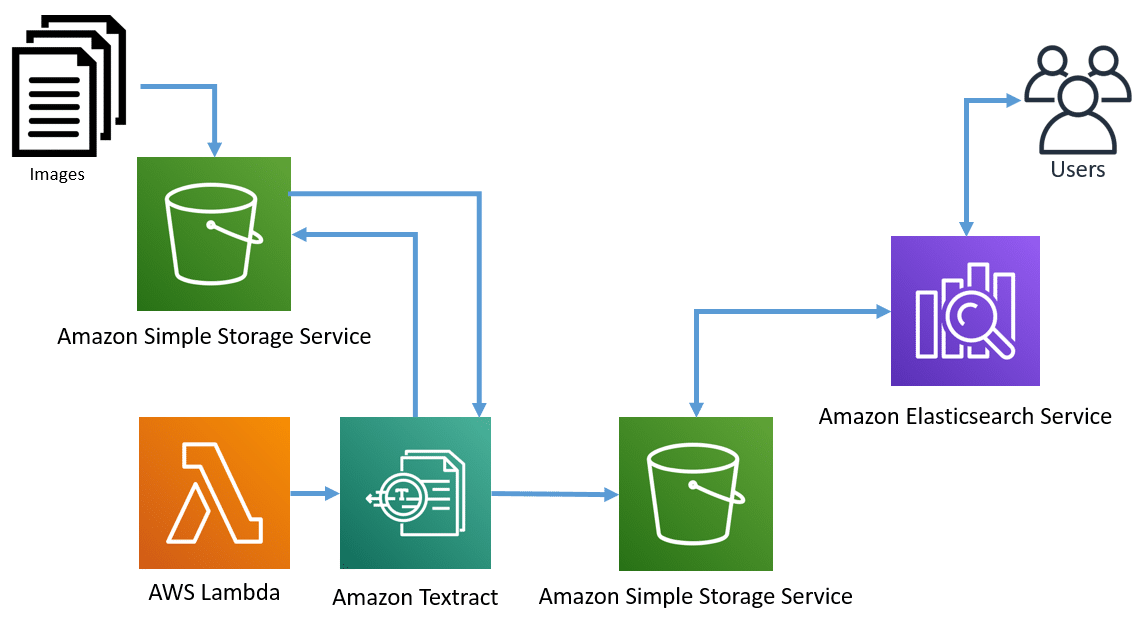
Figure 7 – Simple Textract solution with Amazon Elasticsearch Service
Practical Applications for Textract
While being able to search for information that was extracted from images is useful, it isn’t all that compelling from a business perspective. Information needs to be meaningful and applied to a task so that its value can be recognized. The following examples illustrate common business processes and the role that Textract can play in them.
Human Resource Document Management
Every organization has employees and/or volunteers to support their efforts. There are many state, county, and country regulations that drive what information we need to keep about our employees as well as operational documents about the employees that help us to keep our businesses running. The following are some examples of common documents that most organizations need to collect and retain:
- Employment applications
- Employee resumes
- Interview notes, references, and background information
- Employee offer letters
- Benefit elections
- Employee appraisals
- Wage garnishments
- State and Federal Employee documentation
- Employee disciplinary actions
- Termination decisions and disclosures
- Promotion recommendations
- Employee complaints and investigations
- Leave request documentation
While there are many applications and services available on the market today which will help organizations capture, index, and retain this information, they can sometimes be costly and may not be able to completely capture information held in non-text-based file formats. As discussed earlier, more and more people are using mobile and tablet technologies because of their accessibility and ease of use. In many cases, an employee may use their phone to take a picture of a signed employee document and send it in to the company. This photographed document can cause issues in capturing the information in it, or even classifying it properly in an automated fashion. This is where Textract can easily be integrated into an existing solution, or incorporated as part of a newly constructed solution, to ensure vital information isn’t missed.
The following illustrates how a solution designed for the Cloud-based on Amazon services can facilitate common Human Resource document management activities:
Amazon Services Utilized:
Amazon S3|Amazon WorkDocs|AWS Lambda|Amazon Textract|Amazon API Gateway
Non-Amazon Application examples:
Workday|Oracle Human Capital Management|Oracle PeopleSoft
In this example, a newly hired employee is granted access to the company’s Amazon WorkDocs environment to upload documentation that will be required during the hiring process. While most of the documents being uploaded will be easily indexed and searchable through the Amazon WorkDocs service, the employee has been asked to upload a copy of their driver’s license. The employee utilizes the Amazon WorkDocs mobile application to take a picture of their driver’s license and uploads it to the appropriate folder on their phone. Behind the scenes, the company has configured a workflow in Amazon WorkDocs to inform HR managers when new documents have been submitted and a Human Resources representative reviews the uploaded driver’s license. The human resource representative launches an action in Amazon WorkDocs (a special feature provided by the company’s IT department) which will launch an operation running on AWS Lambda initiating Textract to capture OCR information form the driver’s license as well as create Key-value information which will be sent to the company’s ERP system (like Workday, Oracle Human Capital Management, Oracle PeopleSoft, or other similar application) along with the Amazon WorkDocs reference for where the actual image is stored.
This illustrates a very simple method to directly engage with employees to capture critical HR information through a combination of out-of-the-box Amazon services and some light-weight customizations to create a streamlined process for document storage and data capture. It only took the employee a few seconds to take the picture of the driver’s license and upload it and the HR representative a few seconds to review and process the new document. In fact, the solution could be configured to automatically extract the required details and send it to the ERP without even having to have the HR representative involved for a truly automated solution. Imagine each new hire having ten to twenty documents they need to upload and how much time HR spends processing each document manually for every new employee. Automating this process can amount to several hours a month of time savings, especially when dealing with non-text-based file formats that require someone to manually read the documents to key in the information contained in them. By introducing Amazon Textract into the overall solution, data can be collected, stored, processed, and shared easily and more efficiently.
Business Document Processing and Information Automation
While the Human Resource Document Management example above focused on capturing documents individually as they come in, there are many situations where companies need to process documents in bulk. Using similar AWS services as the previous example, solutions can be designed to allow for batch uploading of documents for processing. As an example, procurement procedures for large purchases can incorporate a wide variety of documentation which may have vastly different processes associated with them. By providing a simple way for files to be uploaded in bulk, AWS services can be utilized to sort through the file formats for processing. Non-text-based image files like JPG, PNG, and PDF files can then be automatically processed by Amazon Textract to capture OCR information, Table data, and Key-value information from forms and then shared with back-office applications, stored in data warehouse services, and/or shared with Amazon Elasticsearch services. Processing hundreds or even thousands of documents and images a month becomes much easier through automation. Incorporating Textract into business process work streams ensures that critical information is identified and captured from structured and semi-structured documents reducing the need for manual classification of information to facilitate business operations like Insurance Claims, Legal Processes, Partner Management, Purchasing, and more.
Litigation is disruptive to normal business operations for any company. Thousands of documents, images, and artifacts have to be reviewed and collected to share with attorneys and the courts during a legal process which can be time-consuming. While there are many discovery tools available on the market today to help speed up the process of finding the desired information, they are reliant on information being in a format that the discovery services can handle. In many cases, important information is stored in pictures and scanned documents that these discovery services cannot easily process. Amazon’s Textract becomes a valuable tool in the discovery process by allowing organizations to quickly filter through image files, capture, and OCR information so that it can become indexed and searched.
Litigation isn’t only a headache for companies, it is a headache for the legal teams associated with the litigation process as well. Imagine a law firm receiving millions of electronic files from a company and having to read through each document to find pertinent information regarding the case they are working on. This can take months and many resources to complete, time that most lawyers don’t have during a case to complete. Files may be images, documents, spreadsheets, audio files, and even video files. All of these need to be processed so that key information can be selected to support the case they are working on. The expense of a large legal process can be staggering due to the sheer amount of manual labor required to gather information. In the following example, Amazon’s Artificial Intelligence and Machine Learning services, including Textract, are utilized to greatly reduce the processing time for legal discovery.
Amazon Services Utilized:
AWS Transfer for SFTP|Amazon S3|AWS Lambda|Amazon Textract|Amazon API Gateway| Amazon Rekognition| Amazon Comprehend| Amazon Transcribe|Amazon Elasticsearch services
In this example, a legal firm utilizes the power of AWS Transfer for SFTP services to allow clients and opposing counsel to quickly upload all of their discovery files and documents which are then automatically stored in Amazon S3. Files are then sorted based on file types for processing. Amazon Textract capture OCR information from image files including table and form data while Amazon Rekognition analyzes photos and videos to identify the objects, people, text, scenes, and activities, perform facial recognition, and detect any inappropriate content. Audio and video files are processed through Amazon Transcribe to capture speech-to-text information. As files are processed, the information is captured and indexed in Amazon Elasticsearch service to enable rich search functionality to the litigators as well as being processed by Amazon Comprehend to quickly find relationships and insights into all the data collected.
What would have taken months to sort through and comprehend becomes manageable information in hours or days providing more time for the legal team to focus on winning their case while saving thousands of dollars on the personnel required to manually process all the discovery information.
The tool you didn’t know you needed
Technology is advancing at incredible speeds and new solutions and services are becoming available every day. Services like Amazon Textract are critical tools in document processing and are rarely thought about but imperative for success. Of all the services Amazon provides, Amazon Textract is one of the hidden gems that can be easily overlooked but deserves to be part of your processing arsenal.
You are not alone
Business solutions can be complex, but making them work for your requirements doesn’t have to be. Clearly defining your goals and objectives is half of the battle, the other half is knowing what tools will help you achieve those goals. Are your off-the-shelf solutions and applications collecting all the information you have? Do you need a business solution to manage all of your documents and data, but don’t know where to start? Are you looking to move off of an outdated legacy application that no longer supports your business direction? You are not alone. Thousands of companies are facing the same questions and are finding the best answers by engaging with experts from Amazon and experts from solution service providers. TekStream Solutions, along with AWS, is excited to speak with you about your Information Processing needs and how the right tools and solutions can have a positive impact on how you conduct business. TekStream Solutions is offering a free Digital Transformation assessment where we will work with you to identify your document processing needs and provide process and technology recommendations to help you transform your business with ease.
Want to learn more about Textract? Contact us today!