
Deep Freeze Your Splunk Data in AWS
By: Zubair Rauf | Splunk Consultant
In today’s day and age, storage has become a commodity, but, even now, reliable high-speed storage comes at a substantial cost. For on-premise Splunk deployments, Splunk recommends RAID 0 or 1+0 disks capable of at least 1200 IOPS and this increases in high-volume environments. Similarly, in bring-your-own-license cloud deployments, customers prefer to use SSD storage with at least 1200 IOPS or more.
Procuring these disks and maintaining them can carry a hefty recurring price tag. Aged data, that no longer needs to be accessed on a daily basis but has to be stored because of corporate governance policies or regulatory requirements, can effectively increase the storage cost for companies if done on these high-performance disks.
This data can securely be moved to Amazon Web Services (AWS) S3, S3 Glacier, or other inexpensive storage options of the Admin’s choosing.
In this blog post, we will dive into a script that we have developed at TekStream which can move buckets from Indexer Clusters to AWS S3 seamlessly, without duplication. It will only move one good copy of the bucket and ignore any duplicates (replicated buckets).
During the process of setting up indexes, Splunk Admins can decide and set data retention on a per-index basis by setting the ‘frozenTimePeriodInSecs’ setting in indexes.conf. This allows the admins to be flexible on their retention levels based on the type of data. Once the data becomes of age, Splunk deletes it or moves it to frozen storage.
Splunk achieves this by referring to the coldToFrozenScript setting in indexes.conf. If a coldToFrozenScript is defined, Splunk will run that script; once it successfully executes without problems, Splunk will go ahead and delete the aged bucket from the indexer.
The dependencies for this script include the following;
– Python 2.7 – Installed with Splunk
– AWS CLI tools – with credentials already working.
– AWS Account, Access Key and Secret Key
– AWS S3 Bucket
Testing AWS Connectivity
After you have installed AWS CLI and set it up with the Secret Key and Access Key for your account, test connectivity to S3 by using the following command:

Note: Please ensure that the AWS CLI commands are installed under /usr/bin/aws and the AWS account you are using should have read and write access to S3 artifacts.
If AWS CLI commands are set-up correctly, this should return a list of all the S3 buckets in your account.
I have created a bucket titled “splunk-to-s3-frozen-demo”.
![]()
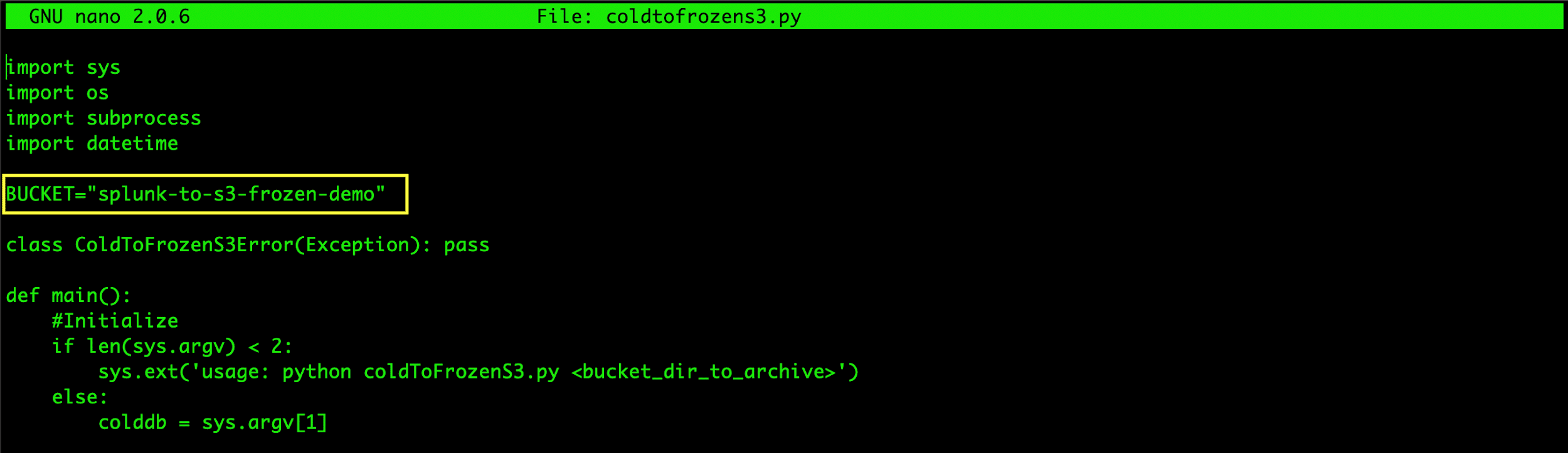
Populate the Script with Bucket Name
Once the S3 bucket is ready, you can copy the script to your $SPLUNK_HOME/bin folder. After copying the script, edit it and change the name of your S3 Bucket where you wish to freeze your buckets.
Splunk Index Settings
After you have made the necessary edits to the script, it is time to update the settings on your index in indexes.conf.
Depending on where your index is defined, we need to set the indexes.conf accordingly. On my demo instance, the index is defined in the following location:

In the indexes.conf, my index settings are defined as follows;

Note: These settings are only for a test index, that will roll any data off to frozen (or delete if a coldToFrozenScript is not present) after 600 seconds.
Once you have your settings complete in indexes.conf, please restart your Splunk instance. Splunk will read the new settings at restart.
After the restart, I can see my index on the Settings > Indexes page.
![]()
Once the index is set up, I use the Add Data Wizard to add some sample data to my index. Ideally, this data should roll over to warm, and the script should be moved to my AWS S3 bucket after 10 minutes.
The remote path on S3 will be set up in the following order:
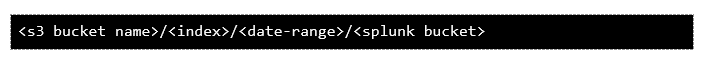
If you are running this on an indexer cluster, the script will not copy duplicate buckets. It will only copy the first copy of a bucket and ignore the rest. This helps manage storage costs and does not keep multiple copies of the same buckets in S3.
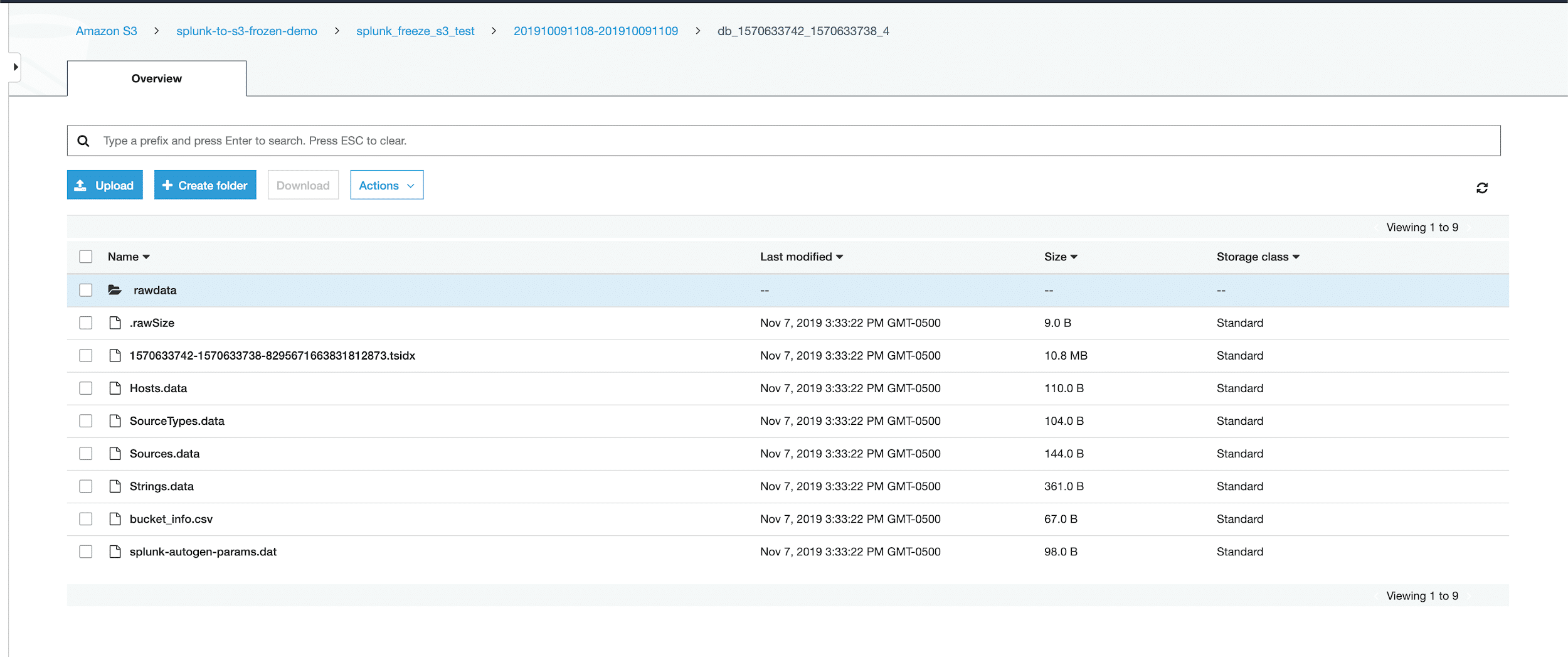
Finally, once the script runs successfully, I can see my frozen Splunk bucket in AWS S3. If you are running this on an indexer cluster, the script will not copy duplicate buckets. It will only copy the first copy of a bucket and ignore the rest. This helps manage storage costs and does not keep multiple copies of the same buckets in S3.
Note: This demo test was done on Splunk Enterprise 8.0 using native Python 2.7.1 that ships with Splunk Enterprise. If you wish to use any other distribution on Python, you will have to modify the script to be compatible.
If there is an error and the bucket does not transfer to S3, or it is not deleted from the source folder, then you can troubleshoot it with the following search:

This search will show you the stdout error that is thrown when the script runs into an error.
To wrap it up, I would highly recommend that you do implement this in a dev/sandbox environment before rolling it out into production. Doing so will ensure that it is robust for your environment and make you comfortable with the set-up.
To learn more about how to set-up AWS CLI Tools for your environment, please refer to the following link; https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html
If you have any questions or are interested in getting the script, contact us today!