

Automated Patching with Ansible and the TekStream MSP

Implementing Right-Click Integrations in Splunk

Deep Freeze Your Splunk Data in AWS
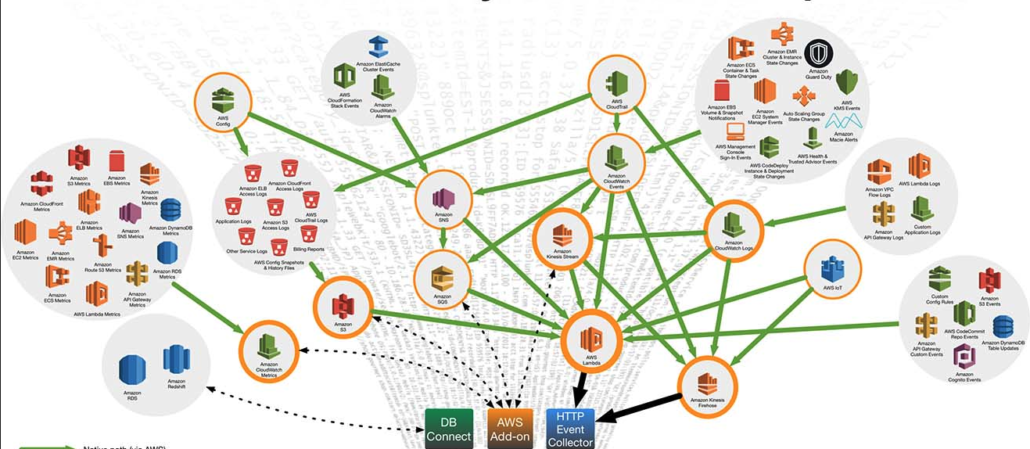
Sneak Peek Into Our Approach to Migrating Splunk On-Prem to AWS How to Migrate Splunk On-Prem to AWS

Optimizing Splunk Searches

We serve cookies on this site to analyze traffic, remember your preferences, and optimize your experience.OkPrivacy Policy